

ElevenLabs has revolutionized text-to-speech technology with the launch of Eleven v3 (Alpha), introducing unprecedented control over AI voice generation through innovative Audio Tags 14. This groundbreaking model transforms simple text narration into dynamic, emotionally rich performances that rival human speech delivery 26. The new system supports over 70 languages and enables creators to direct AI voices with the precision of a film director, using inline tags to control everything from whispered secrets to explosive excitement 123.
This article written in collaboration with Perplexity Labs

Visual guide showing how ElevenLabs v3 audio tags transform text into expressive speech
What Are Audio Tags and Why They Matter
Audio tags are words wrapped in square brackets that the ElevenLabs v3 model interprets as performance cues rather than text to be spoken 16. Unlike previous text-to-speech models that simply read text aloud, v3 performs it with situational awareness and emotional intelligence 213. These tags give users the ability to add emotions like [happy], [excited], and [nervous], delivery styles such as [whispers] and [shouts], and even non-verbal reactions including [laughs], [sighs], and [gulps] 613.
The technology represents a paradigm shift from robotic voice synthesis to expressive AI performance 14. Content creators, audiobook producers, game developers, and video creators can now achieve professional-grade voice acting without requiring human voice talent 410. The model’s deeper contextual understanding allows it to handle emotional transitions, conversational interruptions, and multi-speaker dialogues with remarkable naturalness 12.
Getting Started with ElevenLabs v3
System Requirements and Access
ElevenLabs v3 is currently available in public alpha through the web interface, with an 80% discount available until the end of June 2025 146. Users need an ElevenLabs account to access the v3 model, though API access is not yet publicly available 624. For early API access, users must contact the ElevenLabs sales team 46.
Voice Selection for Optimal Results
The choice of voice significantly impacts audio tag effectiveness 34. Instant Voice Clones (IVC) and designed voices from the ElevenLabs library work best with v3 features, while Professional Voice Clones (PVC) are not yet fully optimized for the new model 1410. The company acknowledges that PVC optimization for v3 is coming in the near future 14. Users should select voices with emotional range in their training data to maximize the impact of audio tags 527.
ElevenLabs settings showing voice, model, stability, similarity, and style exaggeration options slobodskyi
Basic Audio Tag Syntax
The fundamental syntax for audio tags is straightforward: [tag_name] Text to be affected by the tag 16. Tags are case-insensitive, meaning [happy] produces the same result as [HAPPY], though lowercase formatting is recommended for consistency 3. Once applied, tags affect all subsequent text until a new tag is introduced 16. Users can combine multiple tags for layered emotional effects, such as [nervously][whispers] for nervous whispering 213.
Comprehensive Audio Tag Categories
Emotional Expression Tags
ElevenLabs v3 supports a wide range of emotional tags that transform the AI’s vocal delivery 61213. The core emotional tags include [happy] for expressing joy and positivity, [excited] for adding enthusiasm and energy, [sad] for conveying melancholy, [angry] for expressing frustration, [nervous] for showing anxiety, [curious] for indicating interest, and [mischievously] for adding playful elements 1613.
These emotional tags work by providing the AI with contextual cues about the intended mood of the speech 25. The model’s advanced architecture understands text context at a deeper level, allowing it to follow emotional cues and tone shifts more naturally than previous generations 14. For example, using [excited] We won the championship! will produce enthusiastic, high-energy speech that conveys genuine excitement 3.
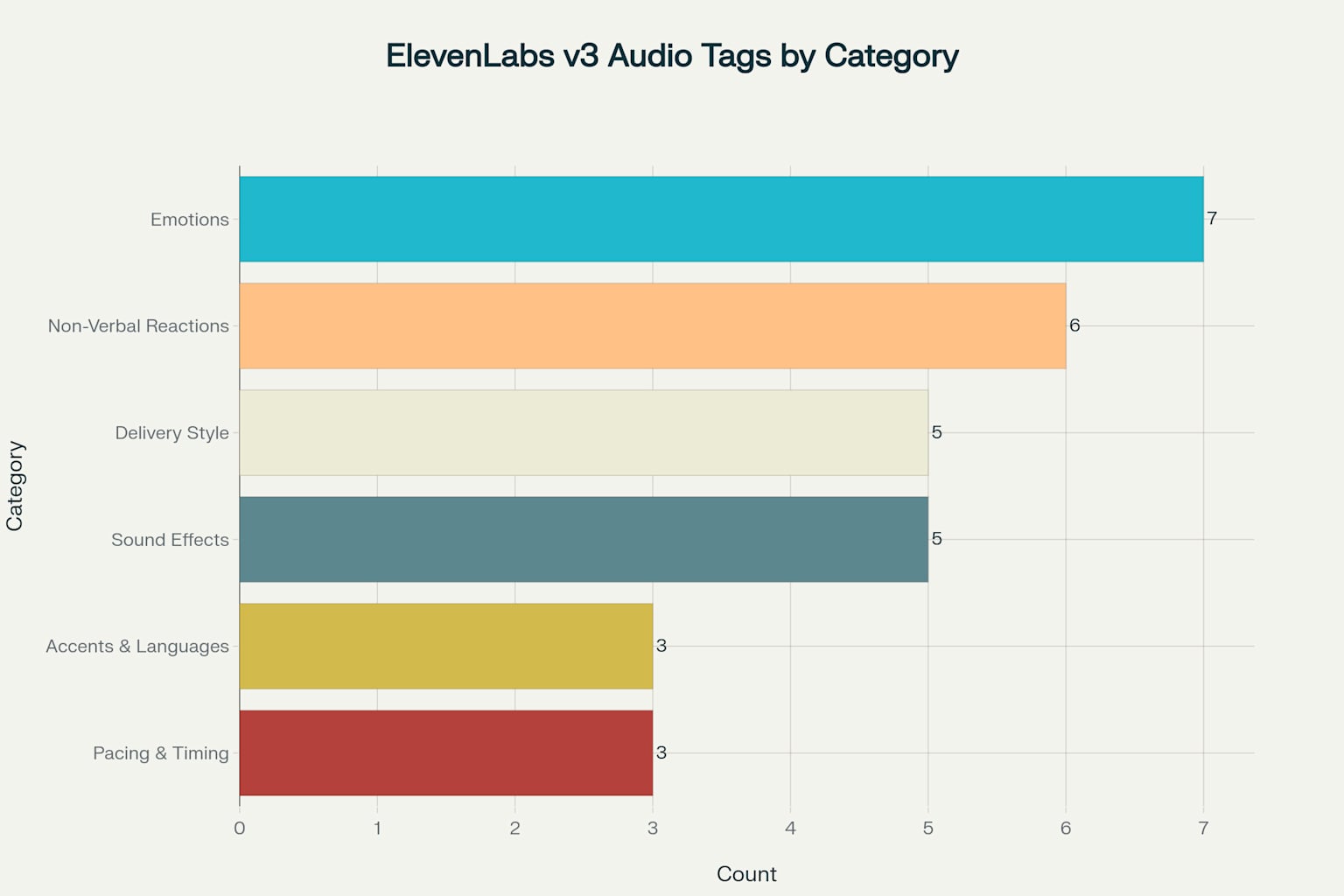
Distribution of ElevenLabs v3 audio tags across different categories, showing the variety of control options available
Delivery Style Control
Delivery style tags give users precise control over volume, pace, and speaking manner 613. The primary delivery tags include [whispers] or [whispering] for intimate, low-volume delivery, [shouts] or [shouting] for dramatic emphasis, and [speaking softly] for gentle, quiet communication 1613. These tags are particularly valuable for creating dynamic narratives where volume changes enhance the storytelling experience 213.
Professional content creators have found delivery style tags especially useful for audiobook production and video narration 410. The ability to seamlessly transition from [whispers] Keep your voice down to [shouts] Everyone listen up! within the same generation eliminates the need for post-production audio editing 113.
Non-Verbal Reactions and Human-Like Sounds
One of v3’s most impressive features is its ability to generate human-like non-verbal reactions through audio tags 613. The model can produce [laughs] or [laughing] for natural laughter, [sighs] for resignation or tiredness, [crying] for deep sadness, [clears throat] for attention-getting sounds, [gulps] for nervous reactions, and [gasp] for surprise or shock 1613.
These non-verbal tags add authenticity to AI-generated speech that was previously impossible to achieve 210. Content creators can now produce realistic conversational audio where speakers react naturally with sounds like “That was hilarious [laughs]” or “Another long day [sighs]” 313.
Sound Effects Integration
ElevenLabs v3 introduces the ability to integrate environmental and action sound effects directly into speech generation 1613. Available sound effect tags include [clapping] for applause, [explosion] for dramatic moments, [gunshot] for action sequences, [door creaks] for atmospheric sounds, and [bird chirping] for environmental ambiance 1613.
This feature opens new possibilities for immersive storytelling and media production 24. Creators can build complete audio narratives with lines like “The old mansion stood before us [door creaks] as we pushed open the heavy wooden door” without requiring separate sound design 313.
Accent and Language Control
The v3 model supports accent modification through specific tags like [strong Russian accent], [British accent], and [French accent] 136. While accent tags can be inconsistent and may not work reliably across all voice types, they represent an innovative approach to multilingual and multicultural content creation 31826. Users should test accent tags with different base voices to find optimal combinations 327.
Pacing and Timing Control
Temporal control tags allow users to manipulate speech rhythm and timing 16. The primary timing tags include [pause] for brief pauses, [long pause] for extended breaks, and [rushed] for accelerated delivery 136. These tags are essential for creating natural conversational flow and dramatic timing 213.
elevenlabs_v3_audio_tags_guide.csv
Generated File
Practical Usage Instructions and Examples
Single Emotion Applications
For basic emotional control, users should place the emotion tag at the beginning of the phrase or sentence 13. A simple example would be [happy] Welcome to our store! We're so glad you're here today! which will produce genuinely cheerful, welcoming speech 3. The key is ensuring the text content matches the emotional intent of the tag 527.
Emotional Transitions and Layering
More sophisticated applications involve transitioning between emotions within a single generation 12. For example: [excited] I can't wait to tell you this news! [pause] [serious] But first, we need to talk about something important demonstrates how users can guide the AI through complex emotional journeys 313. This technique is particularly valuable for narrative content and dramatic presentations 24.
Tag Combinations for Nuanced Expression
Advanced users can combine multiple tags for layered emotional effects 213. Examples include [nervously][whispers] I... I'm not sure this is going to work. [gulps] But let's try anyway or [happily][shouts] We did it! [laughs] I can't believe we actually won! 1313. These combinations create more nuanced and realistic vocal performances 226.
elevenlabs_v3_sample_scripts.csv
Generated File
Multi-Speaker Dialogue Capabilities
Setting Up Dynamic Conversations
ElevenLabs v3’s dialogue mode enables the creation of natural conversations between multiple speakers with realistic pacing and emotional flow 2324. Users can add speakers through the interface, assign different voices to each participant, and use audio tags within individual dialogue lines 24. The model automatically manages speaker transitions, emotional changes, and even conversational interruptions 424.
Natural Interruption Handling
The system excels at creating realistic conversational dynamics where speakers interrupt each other naturally 1224. For example, one speaker might begin explaining something with [explaining] So what you need to do is go to the settings menu and— only to be interrupted by another speaker saying [interrupting] [excited] Oh, I found it! This is exactly what I needed! 324. This capability makes AI-generated dialogues sound spontaneous and authentic 226.
Emotional Context Sharing
Unlike previous text-to-speech models, v3 allows speakers to share emotional context and respond to each other’s moods 123. The model understands conversational flow and can adapt speaker emotions based on the dialogue’s progression 24. This creates more believable multi-character interactions for audiobooks, video content, and interactive media 423.
Advanced Techniques and Best Practices
Contextual Enhancement Strategies
Successful audio tag implementation requires providing sufficient context around tagged phrases 1527. The model considers surrounding text when interpreting emotional cues, so longer passages often produce more consistent results 527. Users should write descriptive text that supports the intended emotional tags rather than relying solely on the tags themselves 527.
Voice Settings Optimization
Users can enhance audio tag effectiveness by adjusting voice settings appropriately 527. Lower stability settings (25-50%) can add more emotional variety, while higher similarity settings (70-90%) maintain voice consistency 1427. The style exaggeration setting can amplify the impact of emotional tags when used judiciously 521.
Regeneration and Iteration Strategies
ElevenLabs v3 requires more prompt engineering than previous models, and results can vary between generations 1426. Users should generate multiple versions of the same script and select the best result 327. Small adjustments to text or tag placement can significantly improve output quality 27. The model’s nondeterministic nature means that persistence and experimentation are key to achieving optimal results 1526.
Punctuation and Formatting Enhancement
Proper punctuation significantly impacts audio tag effectiveness 5727. Ellipses (…) create natural pauses, capital letters add emphasis, and standard punctuation helps establish rhythm 35. For example, [tired] It was a long day... [sighs] Nobody listens anymore uses punctuation to enhance the emotional impact of the tags 35.
Troubleshooting Common Issues
Tags Being Read Aloud
One of the most common issues users encounter is audio tags being spoken rather than interpreted 31126. This typically occurs when using incompatible voice types or older model versions 326. Solutions include ensuring the v3 model is selected, using Instant Voice Clones instead of Professional Voice Clones, and regenerating the audio multiple times for consistency 1326.
Inconsistent Emotional Output
Users often experience inconsistent results where the same script produces different emotional outputs 32627. This can be addressed by adding more contextual information around tagged phrases, using descriptive text that matches the intended emotion, and adjusting voice settings for more or less variation 527. The alpha nature of v3 means some inconsistency is expected 1426.
Sound Effects Not Registering
Sound effect tags can be subtle or inconsistent across different voices and contexts 31826. Users should try different sound effect tags, combine them with delivery tags like [excited][clapping], and regenerate multiple times as effects implementation can vary 318. Some sound effects work better with certain voice types and contexts 326.
Limited Accent Implementation
Accent tags may not always produce noticeable changes, particularly with certain voice types 31826. Users should experiment with stronger accent specifications like [strong British accent], test different base voices for accent compatibility, and understand that accent features are still being refined in the alpha version 326.
Signal wave of an audio file labeled as “SAD”, visualizing amplitude over time projectpro
Professional Applications and Use Cases
Content Creation and Media Production
ElevenLabs v3 has found significant adoption among content creators working on videos, audiobooks, and multimedia projects 41025. The technology enables solo creators to produce professional-quality multi-character content without hiring voice actors 425. YouTube creators, filmmakers, and game developers are leveraging audio tags to create more engaging, emotionally resonant content 42526.
Educational and Accessibility Applications
The enhanced expressiveness of v3 makes it valuable for educational content where emotional engagement improves learning outcomes 412. The technology also provides new accessibility options for individuals who need text-to-speech services but require more natural, engaging voice output 412. The multi-language support and emotional range make it suitable for global educational initiatives 14.
Interactive Media and Gaming
Game developers and interactive media creators are using v3’s multi-speaker dialogue capabilities to create dynamic character interactions 2426. The ability to generate emotional responses and natural conversations enables more immersive gaming experiences and interactive storytelling 24. The sound effects integration allows for comprehensive audio design within a single generation workflow 14.
Future Developments and Considerations
Technology Evolution
ElevenLabs acknowledges that v3 is in alpha stage with ongoing improvements planned 1426. The company is working on optimizing Professional Voice Clones for v3, developing real-time versions of the model, and expanding API access 146. Users should expect continued refinements in tag consistency and expanded tag libraries 14.
Cost and Accessibility
Currently offered at an 80% discount through June 2025, the full pricing structure for v3 will be significantly higher than previous models 4826. This pricing may limit accessibility for some users, though the company’s commitment to advancing the technology suggests continued development of more affordable options 426.
Competitive Landscape
As v3 demonstrates the potential of highly expressive AI voice generation, competitors are likely to develop similar technologies 26. Open-source alternatives may emerge that challenge ElevenLabs’ market position, particularly if training data and techniques become more widely available 26. Users should consider both the current capabilities and long-term strategic positioning when investing in v3-based workflows 26.
elevenlabs-v3-audio-tags-guide.md
Generated File
Conclusion
ElevenLabs v3 represents a fundamental shift from traditional text-to-speech toward dynamic voice performance, offering unprecedented control over AI-generated speech through innovative audio tags 14. The technology enables creators to direct emotional expression, delivery style, non-verbal reactions, and even environmental sound effects with remarkable precision 1613. While the alpha version requires patience and experimentation, the results demonstrate the future potential of AI voice generation 1426.
Success with v3 requires understanding that users are directing a performance rather than simply generating speech 12. The key to mastering audio tags lies in experimentation, contextual awareness, and persistence through the regeneration process 327. As the technology continues to evolve from alpha to full release, early adopters who master these techniques will be well-positioned to leverage the full potential of expressive AI voice generation 1426.
The integration of emotional intelligence, multi-speaker capabilities, and sound effects represents a convergence toward truly interactive AI communication 124. For content creators, educators, and media professionals, ElevenLabs v3 opens new creative possibilities that were previously available only through human voice acting 425. The future of AI voice generation has arrived, and it speaks with unprecedented emotional depth and authenticity 14.
- https://elevenlabs.io/blog/v3-audiotags
- https://elevenlabs.io/hi/blog/eleven-v3-situational-awareness
- https://www.reddit.com/r/ElevenLabs/comments/1l3fsgk/v3_alpha_support_documentation_copied_from_eleven/
- https://elevenlabs.io/blog/eleven-v3
- https://help.elevenlabs.io/hc/en-us/articles/14187482972689-How-to-produce-emotions
- https://help.elevenlabs.io/hc/en-us/articles/35869142561297-How-do-audio-tags-work-with-Eleven-v3-Alpha
- https://www.reddit.com/r/ElevenLabs/comments/11ftdss/how_do_you_put_emotions_into_the_voice/
- https://www.reddit.com/r/ElevenLabs/comments/1l46hy4/introducing_eleven_v3_alpha/
- https://elevenlabs.io/docs/models
- https://the-decoder.com/elevenlabs-eleven-v3-lets-ai-voices-whisper-laugh-and-express-emotions-naturally/
- https://www.reddit.com/r/ElevenLabs/comments/1bzblm9/making_tts_with_emotions/
- https://www.aibase.com/news/www.aibase.com/news/18702
- https://elevenlabs.io/pl/blog/eleven-v3-situational-awareness
- https://www.youtube.com/watch?v=1dSWgHDEUW0
- https://elevenlabs.io/docs/capabilities/text-to-speech
- https://www.youtube.com/watch?v=yzwjI4yTES8
- https://www.youtube.com/watch?v=zv_IoWIO5Ek
- https://www.youtube.com/watch?v=4yWjbqnQtuc
- https://www.segmind.com/models/eleven-labs-transcript/api
- https://elevenlabs.io/docs/capabilities/sound-effects
- https://docs.livekit.io/agents/integrations/elevenlabs/
- https://www.youtube.com/watch?v=46NrwlKZdMU
- https://elevenlabs.io/v3
- https://help.elevenlabs.io/hc/en-us/articles/35869170509201-What-is-Dialogue-mode
- https://www.linkedin.com/posts/a-banks_elevenlabs-just-dropped-v3-the-output-is-activity-7336723549958680576-777N
- https://www.roborhythms.com/elevenlabs-v3-whats-new/
- https://www.reddit.com/r/ElevenLabs/comments/1fzt965/what_are_your_tips_and_tricks_for_using/
- https://elevenlabs.io/docs/best-practices/prompting/eleven-v3
- https://x.com/elevenlabsio/status/1930689774278570003
- https://tech-now.io/en/blogs/elevenlabs-v3-next-gen-ai-voices-features-use-cases-pricing-2025
- https://elevenlabs.io/docs/conversational-ai/best-practices/prompting-guide
- https://x.com/elevenlabsio/status/1931428960782692737
- https://elevenlabs.io/blog/creating-multi-turn-dialogues-with-conversational-ai-and-text-to-speech
























